
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
Tags
- 지연로딩
- 스토어드 프로시저
- dfs
- fetch
- PS
- 동적sql
- JPQL
- FetchType
- 낙관적락
- 연결리스트
- SQL프로그래밍
- 비관적락
- 이진탐색
- 백트래킹
- 즉시로딩
- 힙
- 다대일
- 데코레이터
- 연관관계
- 일대다
- CHECK OPTION
- exclusive lock
- execute
- BOJ
- 스프링 폼
- 다대다
- 유니크제약조건
- eager
- shared lock
- querydsl
Archives
- Today
- Total
흰 스타렉스에서 내가 내리지
웹 크롤링 4 - selenium을 이용해 동적수집을 해보자 본문
728x90
Selenium은 프로그램을 이용해 자동화된 웹 테스트를 수행할 수 있도록 해주는 프레임워크다.
크롭드라이버를 현재 내 컴퓨터에 설치된 크롬의 버전에 맞는 걸로 다운로드 받고, 원하는 경로에 저장한다.
나는 메인코드를 실행하는 폴더에 같이 넣었다.
from selenium import webdriver
driver = webdriver.Chrome('./chromedriver')
driver.get('https://www.naver.com')실행하면 네이버가 켜질 것이다.
1. get() 함수
매개변수로 이동할 주소를 넣어줌.
함수명에서 직관적으로 무슨 역할을 하는지 알 수 있겠다.
2. find_element_by_ ~~ 함수
대표적으로 4가지 종류가 있는데,
- find_element_by_id()
- find_element_by_class_name()
- find_element_by_css_selector()
- find_element_by_xpath()
id랑 class 명으로 찾는 함수는 . 이나 #을 붙여줄 필요가 없다.
find_element는 처음 나오는 한개만 찾고 그 요소를 리턴하는데, 해당하는 모든걸 찾아 배열로 리턴하는 함수는 find_elements_~~이다.
3. send_keys() 함수
input 등 텍스트를 입력할 수 있는 HTML 요소에,
send_keys( )의 매개변수로 전달된 텍스트를 입력할 수 있다,
from selenium import webdriver
driver = webdriver.Chrome('./chromedriver')
driver.get('https://www.naver.com')
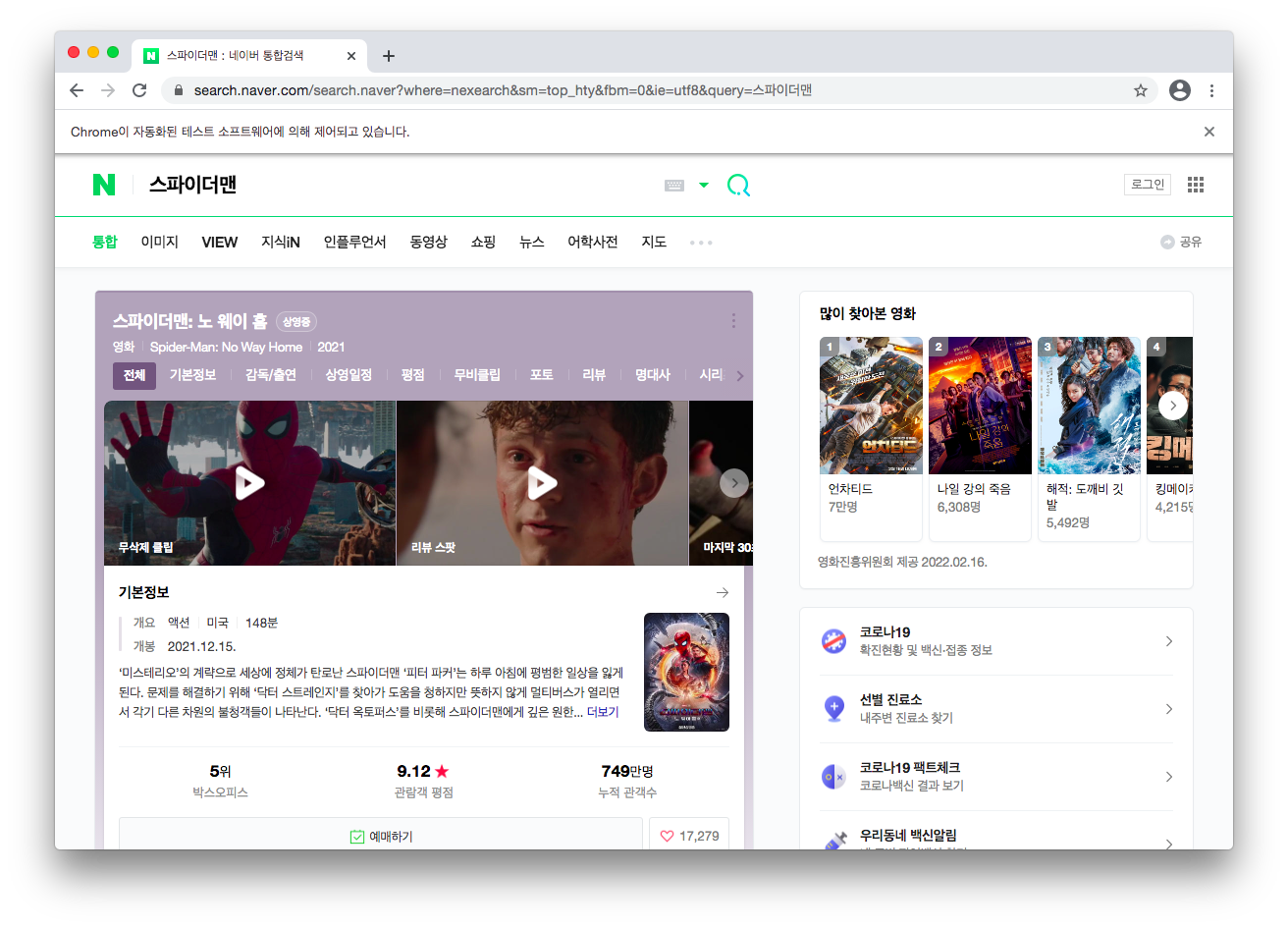
driver.find_element_by_css_selector('#query').send_keys('스파이더맨')

4. click() 함수
설명이 필요없다. 바로 코드를 보자.
from selenium import webdriver
driver = webdriver.Chrome('./chromedriver')
driver.get('https://www.naver.com')
driver.find_element_by_css_selector('#query').send_keys('스파이더맨')
driver.find_element_by_css_selector('#search_btn').click()
5. page_source
만약 로그인해야만 들어갈 수 있는 웹 페이지라면, requests 라이브러리로는 그 페이지의 소스코드를 불러올 수 없을 것이다.
이에 대한 해결방법은, 웹드라이버로 조작해서 들어간다음, 소스코드를 가져오는 것.
자세한 건 아래 코드를 보자.
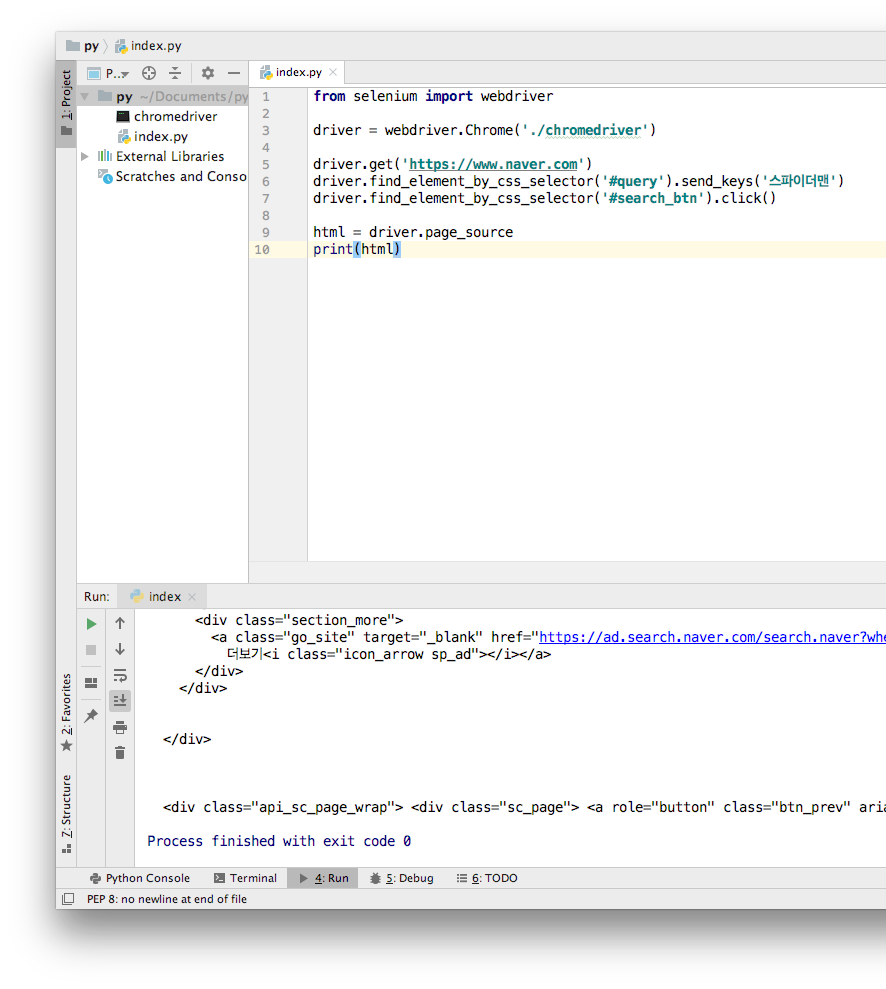
여기서, html은 String 타입이다.
BeautifulSoup 라이브러리를 이용하여 html 요소들을 탐색할 수 있게 된다.
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Chrome('./chromedriver')
driver.get('https://www.naver.com')
driver.find_element_by_css_selector('#query').send_keys('스파이더맨')
driver.find_element_by_css_selector('#search_btn').click()
html = driver.page_source
print(type(html))
html_soup = BeautifulSoup(html, 'html.parser')
print(type(html_soup))
# <class 'str'>
# <class 'bs4.BeautifulSoup'>
'Web Crawling' 카테고리의 다른 글
| 웹 크롤링 3 - 크롤링한 데이터들을 파일에 저장하기 (0) | 2022.02.17 |
|---|---|
| 웹 크롤링 2 - 네이버 금융에서 시가총액 상위 기업들 크롤링하기 (0) | 2022.02.17 |
| 웹 크롤링 1 - requests, bs4 라이브러리 (0) | 2022.02.17 |
'Web Crawling' Related Articles
more


