
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 다대다
- 유니크제약조건
- shared lock
- 백트래킹
- 일대다
- 비관적락
- execute
- BOJ
- PS
- JPQL
- 동적sql
- 데코레이터
- dfs
- 낙관적락
- 연결리스트
- 스프링 폼
- 즉시로딩
- SQL프로그래밍
- 스토어드 프로시저
- 힙
- 다대일
- exclusive lock
- fetch
- 이진탐색
- 지연로딩
- CHECK OPTION
- eager
- 연관관계
- FetchType
- querydsl
Archives
- Today
- Total
흰 스타렉스에서 내가 내리지
웹 크롤링 1 - requests, bs4 라이브러리 본문
728x90
import requests
from bs4 import BeautifulSoup
request = requests.get('https://www.google.com')
raw = request.text
html = BeautifulSoup(raw, 'html.parser')requests와 BeautifulSoup라는 클래스가 있다.
requests는 웹 페이지에 요청할 수 있는 기능들을 모아놓은 클래스이다.
get() 함수에 매개변수로 어느 웹 사이트의 주소를 넣으면, 해당 웹사이트에 대한 정보가 담겨있는 requests객체가 반환된다.
raw변수는 사실 html문서가 아닌 String 타입의 그녕 문자열일 뿐이다.
BeautifulSoup는 String 타입의 값을 살아있는 HTML문서로 바꿔준다.
따라서 html변수는 태그, 클래스 하나하나가 웹 페이지와 같은 의미를 가지고 있다.
print(type(raw))
print(type(html))

html.select() 함수를 사용하면, html변수에 담긴 HTML문서 안에서 입력된 선택자를 갖는 요소를 리스트 타입으로 모두 가져온다
html.select_one() 함수를 사용하면, 매개변수로 지정된 경로에 일치하는 요소들 중 맨 처음 나오는 하나를 리턴한다,
태그를 다 빼고, text content만 가져오고 싶다면 text 프로퍼티애 접근하면 된다.
selector = html.select_one('#NM_FAVORITE > div.group_nav > ul.list_nav.type_fix > li:nth-child(6) > a > span')
print(selector)
print(selector.text)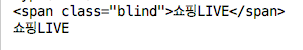
'Web Crawling' 카테고리의 다른 글
| 웹 크롤링 4 - selenium을 이용해 동적수집을 해보자 (0) | 2022.02.17 |
|---|---|
| 웹 크롤링 3 - 크롤링한 데이터들을 파일에 저장하기 (0) | 2022.02.17 |
| 웹 크롤링 2 - 네이버 금융에서 시가총액 상위 기업들 크롤링하기 (0) | 2022.02.17 |
'Web Crawling' Related Articles
more


