
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- BOJ
- exclusive lock
- 비관적락
- 동적sql
- PS
- FetchType
- 유니크제약조건
- CHECK OPTION
- SQL프로그래밍
- 연관관계
- eager
- 연결리스트
- JPQL
- 즉시로딩
- 다대다
- 데코레이터
- fetch
- dfs
- 일대다
- execute
- 백트래킹
- 힙
- querydsl
- 다대일
- 지연로딩
- shared lock
- 이진탐색
- 스토어드 프로시저
- 낙관적락
- 스프링 폼
Archives
- Today
- Total
흰 스타렉스에서 내가 내리지
OCR (광학 문자 인식) 도구 : tesseract 본문
728x90
pytesseract 는 Python 에서 사용할 수 있는 OCR (광학 문자 인식) 도구이다.
Tesseract-OCR 엔진을 기반으로 하며, 이미지에서 텍스트를 추출하는 데 사용된다.
설치하고 사용하기 위해서는 먼저 Tesseract-OCR 엔진이 시스템에 설치되어 있어야 한다.
Mac 에서는 Homebrew 를 사용하여 Tesseract-OCR 엔진을 설치한다.
brew install tesseract
Tesseract-OCR 엔진이 설치되었다면, Python 환경에 pytesseract 를 설치한다.
pip 명령어를 사용한다.
pip3 install pytesseractpip3 install pillow
from PIL import Image
import pytesseract
import cv2
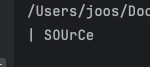
path = 'source.png'
# 이미지를 불러옴
img = cv2.imread(path)
# 그레이스케일로 변환
gray_image = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 변환된 이미지를 저장
cv2.imwrite('gray_' + path, gray_image)
# 이미지 파일 경로
image_path = './' + 'gray_' + path
# 이미지 로드
img = Image.open(image_path)
# pytesseract 를 사용하여 이미지에서 텍스트 추출
text = pytesseract.image_to_string(img, lang='eng')
print(text)

opencv 라이브러리를 이용하여, 컬러이미지를 그레이스케일로 변환한 후, OCR 도구인 tesseract 를 이용하여 문자 인식을 진행한다.
잘 인식 되었다.
'Python' 카테고리의 다른 글
| 정렬 : compare() 직접 정의 - functools.cmp_to_key (0) | 2024.04.24 |
|---|---|
| 파이썬 내장 Statistics 라이브러리 (1) | 2024.01.11 |
| api 가져오기 (0) | 2022.06.09 |
| API로 날씨 정보 가져오기 (0) | 2022.05.15 |
| [PYTHON] 배열에서 가장 많이 나온 원소를 구하는 법 (0) | 2022.03.08 |