
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- querydsl
- fetch
- BOJ
- 지연로딩
- 일대다
- eager
- exclusive lock
- 연결리스트
- PS
- shared lock
- 이진탐색
- 백트래킹
- 연관관계
- 다대일
- JPQL
- 낙관적락
- dfs
- CHECK OPTION
- 스토어드 프로시저
- 유니크제약조건
- 즉시로딩
- execute
- 동적sql
- 다대다
- FetchType
- 데코레이터
- 스프링 폼
- SQL프로그래밍
- 힙
- 비관적락
- Today
- Total
흰 스타렉스에서 내가 내리지
프로메테우스 & 그라파나 본문
# 프로메테우스
- 애플리케이션에서 발생한 메트릭을, 그 순간 뿐이 아닌 과거 이력까지 확인하려면 메트릭을 보관하는 DB가 필요하다.
- 프로메테우스는 메트릭을 지속해서 수집하고 저장하는 DB 역할을 한다.
# 그라파나
- 프로메테우스가 DB이면, 이 DB에 있는 데이터를 불러와서 사용자에게 보여주는 대시보드가 필요하다.
- 그라파나는 매우 유연하고, 데이터를 그래프로 보여주는 툴이다.
- 프로메테우스를 포함한 다양한 데이터소스를 지원한다.
# 프로메테우스 - 애플리케이션 설정
프로메테우스가 우리 애플리케이션의 메트립을 수집하도록 연동하는데 필요한 2가지 작업
1. 애플리케이션 설정 : 프로메테우스 포멧에 맞추어 메트릭 만들기
2. 프로메테우스 설정 : 프로메테우스가 우리 애플리케이션의 메트릭을 주기적으로 수집하도록 설정

* build.gradle 추가
implementation 'io.micrometer:micrometer-registry-prometheus' //추가
- 마이크로미터 프로메테우스 구현 라이브러리를 추가한다.
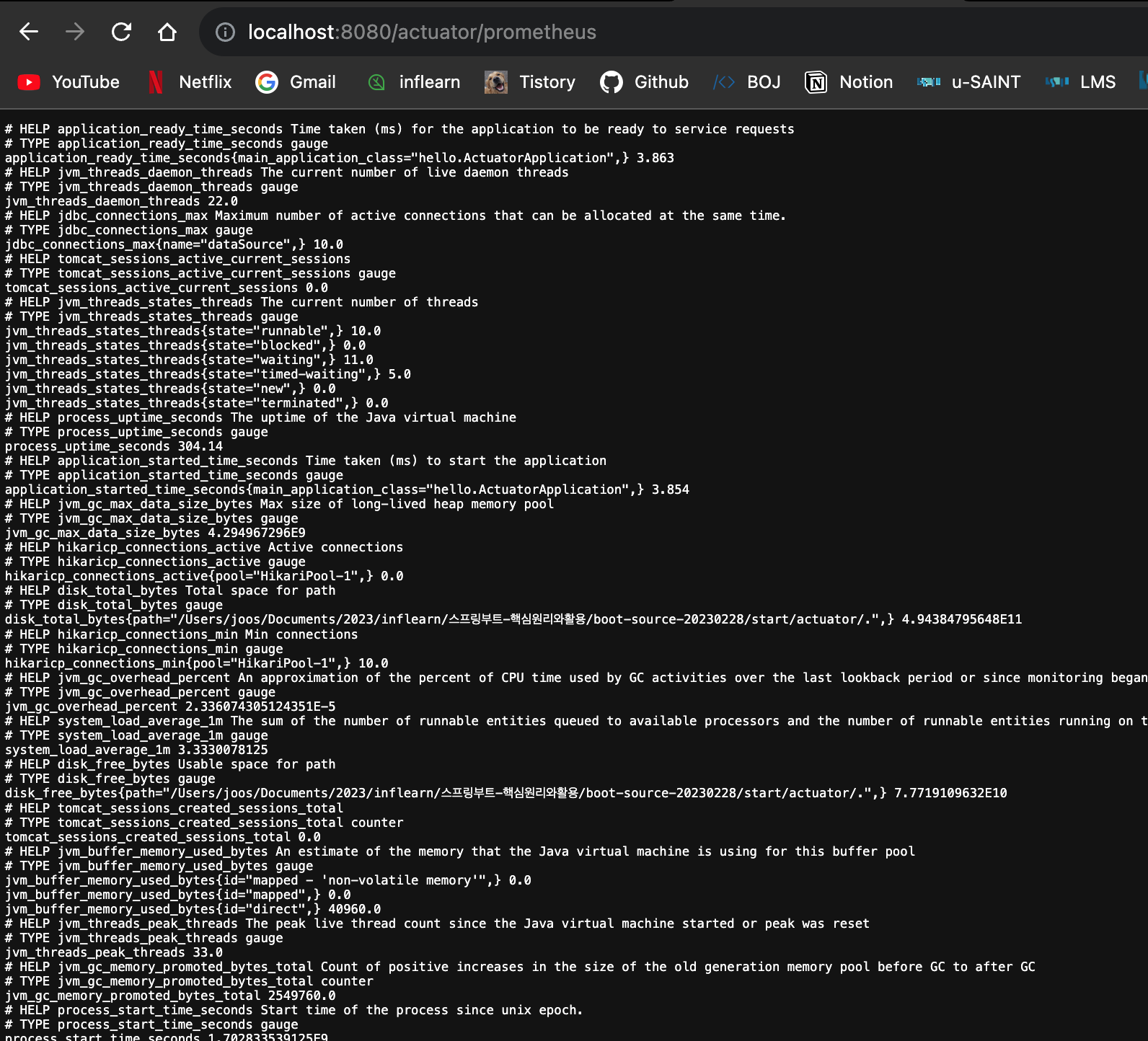
- 엔드포인트에 /{prometheus} 가 추가된다.
- 이렇게 하면 스프링부트와 액츄에이터가 자동으로 마이크로미터 프로메테우스 구현체를 등록해서 동작하도록 설정해준다.
http://localhost:8080/actuator/prometheus
# 프로메테우스 - 수집 설정
- 프로메테우스가 애플리케이션의 /actuator/prometheus 를 호출해서 메트릭을 주기적으로 수집하도록 해야한다.
- 이를 위해 프로메테우스 폴더에 있는 prometheus.yml 파일을 수정한다.
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
# 내가 추가!!
- job_name: "spring-actuator"
metrics_path: "/actuator/prometheus"
scrape_interval: 1s
static_configs:
- targets: ["localhost:8080"]
- 윗 부분은 기본으로 써져 있던 거고, 맨 아래 부분 내가 추가 한 부분만 따로 써준다.
- job_name: 수집하는 이름. 임의의 이름을 사용하면 된다
- metrics_path: 수집할 경로를 지정
- scrape_interval: 수집할 주기 설정.
→ 수집 주기의 기본 값은 1m 이다. 수집 주기가 너무 짧으면 앱 성능에 영향을 줄 수 있으므로 운영에서는 10s ~ 1m 권장
- targets: 수집할 서버의 IP, PORT 지정
* yml을 고쳤으니 prometheus 재시작!

http://localhost:9090



- 우리가 연동한 애플리케이션의 메트릭 정보를 볼 수 있다.
- UP 이면 정상적으로 잘 수집하고 있는 것
# 프로메테우스 - 기본 기능

- error, exception, instance, job, method, outcome, status, uri 는 각각의 메트릭 정보를 구분해서 사용하기 위한 태그이다.
- 마이크로미터에서는 태그(Tag) 라 하고, 프로메테우스에서는 레이블(Label) 이라 한다.
* 특정 시간에서의 메트릭 값 확인하기
* 필터링 사용하기

- 필터는 중괄호 ( {} ) 문법을 사용한다.
* 레이블 일치 연산자
☞ = 제공된 문자열과 정확히 동일한 레이블 선택
☞ != 제공된 문자열과 같지 않은 레이블 선택
☞ =~ 제공된 문자열과 정규식 일치하는 레이블 선택
☞ !~ 제공된 문자열과 정규식 일치하지 않는 레이블 선택
예)
- uri=/log , method=GET 조건으로 필터
☞ http_server_requests_seconds_count{uri="/log", method="GET"}
- /actuator/prometheus 는 제외한 조건으로 필터
☞ http_server_requests_seconds_count{uri!="/actuator/prometheus"}
- method 가 GET , POST 인 경우를 포함해서 필터
☞ http_server_requests_seconds_count{method=~"GET|POST"}
- /actuator 로 시작하는 uri 는 제외한 조건으로 필터
☞ http_server_requests_seconds_count{uri!~"/actuator.*"}
* 연산자 쿼리와 함수
다음과 같은 연산자를 지원한다.
+ (덧셈)
- (빼기)
* (곱셈)
/ (분할)
% (모듈로)
^ (승수/지수)
sum
값의 합계를 구한다.
예) sum(http_server_requests_seconds_count)
sum by
sum by(method, status)(http_server_requests_seconds_count)- SQL의 group by 기능과 유사하다.
결과
{method="GET", status="404"} 3
{method="GET", status="200"} 120
count
count(http_server_requests_seconds_count)
메트릭 자체의 수 카운트
topk
topk(3, http_server_requests_seconds_count)
상위 3개 메트릭 조회
오프셋 수정자
http_server_requests_seconds_count offset 10m
offset 10m 과 같이 나타낸다. 현재를 기준으로 특정 과거 시점의 데이터를 반환한다.
범위 벡터 선택기
http_server_requests_seconds_count[1m]
마지막에 [1m] , [60s] 와 같이 표현한다. 지난 1분간의 모든 기록값을 선택한다.
참고로 범위 벡터 선택기는 차트에 바로 표현할 수 없다. 데이터로는 확인할 수 있다.
범위 벡터 선택의 결과를 차트에 표현하기 위해서는 약간의 가공이 필요한데, 조금 뒤에 설명하는 상대적인 증가 확인 방법을 참고하자.
# 프로메테우스 - 게이지와 카운터
* 게이지
- 오르내릴 수 있는 값
- 예) CPU, 메모리 사용량, 커넥션
* 카운터
- 단순하게 증가하는 단일 누적 값
- 예) HTTP 요청 수, 로그 발생 수
* 게이지

* 카운트
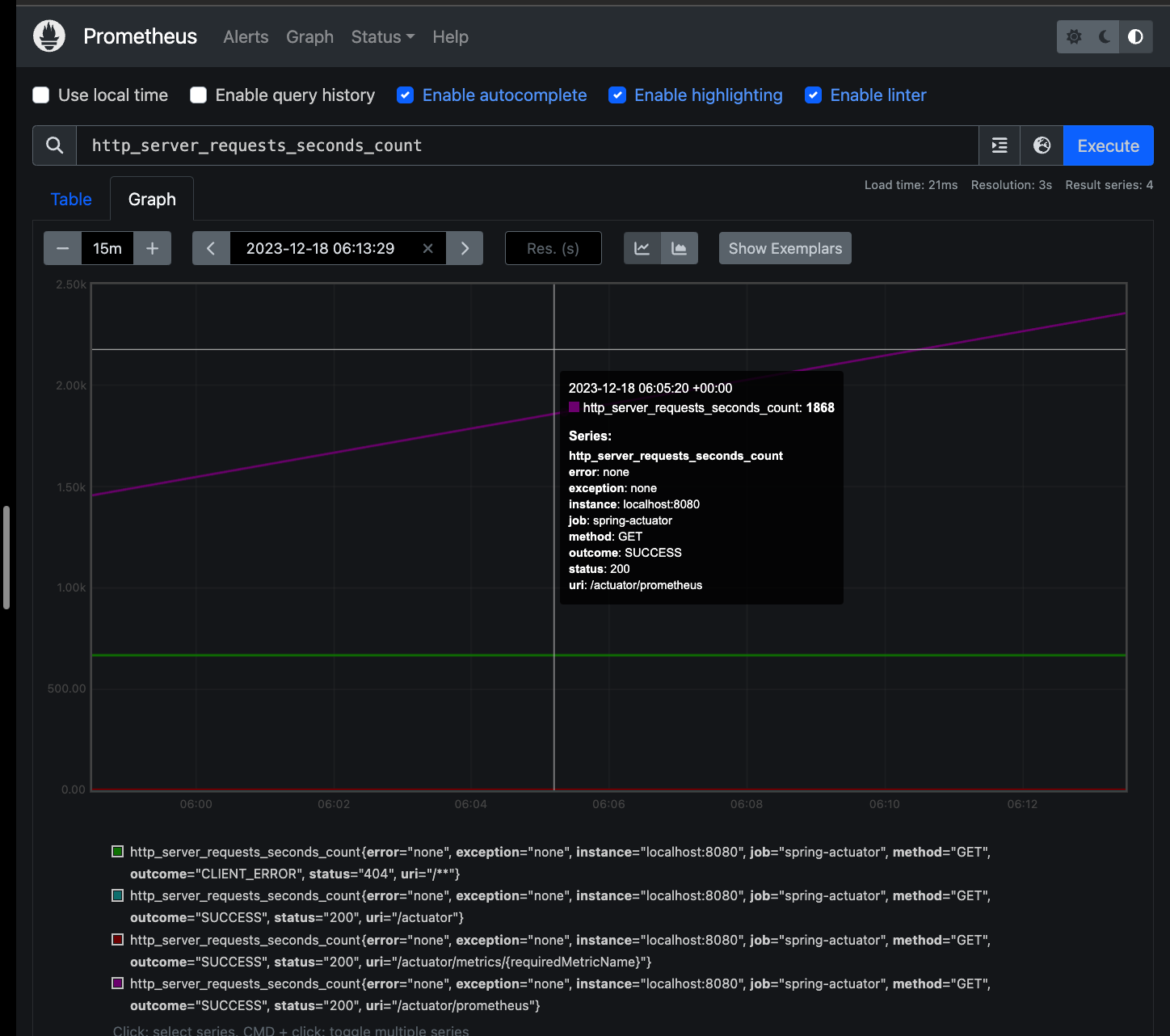
- 고객의 HTTP 요청 수 누적값을 그래프로 표현
- 이런 그래프는 특정 시간에 얼마나 요청이 들어왔는지 한눈에 확인하기 어렵기 때문에 increase(), rate() 함수를 지원한다.
* increase()
- 마지막에 [시간] 을 이용해서 범위 벡터를 선택해야 한다.
increase(http_server_requests_seconds_count{uri="/log"}[1m])
* rate()
- 범위 벡터에서 초당 평균 증가율을 계산한다.
- increase() 가 숫자를 직접 카운트 한다면, rate()는 여가에 초당 평균을 나누어서 계산한다.
- rate(data[1m]) 에서 [1m] 이라고 하면 60초가 기준이 되므로 60을 나눈 수이다.
- rate(data[2m]) 에서 [2m] 이라고 하면 120초가 기준이 되므로 120을 나눈 수이다.
- 초당 얼마나 증가하는지 나타내는 지표로 보면 된다.
* irate()
- rate와 유사한데, 범위벡터에서 초당 순간 증가율을 계산한다.
- 급격하게 증가한 내용을 확인하기 좋다.
** 프로메테우스는 한눈에 들어오는 대시보드를 만들기 어렵다는 단점이 있다. 이 부분은 그라파나를 사용한다.
# 그라파나 - 현 version 10.2.2
* 그라파나 설치 그리고 로그인
brew install grafana
brew services start grafanahttp://localhost:3000
id: admin, pw : admin

애플리케이션 켜고 → 프로메테우스 켜고 → 그라파나 켜고
* 그라파나에서 프로메테우스 연동

Connection에 프로메테우스 설치 url을 넣어야 하는데, 내 애플리케이션의 프로메테우스 링크를 넣어주자.

그리고 Save & test 버튼을 누르면 API 연경 성공이라고 나온다.
# 그라파나 - 대시보드 만들기


1. Dashboards 메뉴 선택
2. New -> New Dashboard 선택 or Create Dashboard 버튼 선택

* 패널 만들기

- 아래 Run queries 버튼 오른쪽에 Builder, Code 라는 버튼이 보이는데, Code 를 선택
- "Enter a PromQL query..." 라는 부분에 메트릭을 입력하면 된다.

- 패널에 시스템 CPU 사용량을 그래프로 확인할 수 있다.
- 시스템 CPU 뿐만 아니라 프로세서 CPU도 동시에 같이 보고 싶다면, 좌측하단 "+Add query" 버튼을 누른다.

* 범례(legend) 바꾸기


- 좌측 하단데 options를 선택하면 Legend 입력 박스에 Custom 을 선택하면 내가 원하는 값으로 범례를 설정할 수 있다.
* 패널 이름 설정

- 우측 바에, Panel options에서 패널의 제목 (title) 을 설정할 수 있다.
* 패널 저장하기

화면 오른쪽 상단의 Save 또는 Apply 버튼을 선택하면 추가된 패널을 확인할 수 있다.
* 하나 더 해보자 - 디스크 사용량
disk_total_bytes 가 있고 disk_free_bytes가 있다.
그러면 디스크 사용량은 (disk_total_bytes) - (disk_free_bytes) 일 것이다.

- 데이터 용량의 기본 단위는 바이트이다.
- 우측 바에 보면 Standard options 라는 게 있다.


- 데이터 단위를 바꿔주면 쉽게 읽을 수 있다.
- 그래프는 최솟값과 최대값 기준으로 나타나고 있다.


- 우측 바에서 Min 값을 0으로 해주면, 그래프를 0부터 표시해준다.
- 이렇게 하고 Apply를 누르면,

- 이렇게 하면 CPU 사용량과 디스크 사용량을 실시간으로 모니터링할 수 있다.
- 이런식으로, 다음의 메트릭들을 하나하나 추가하면 된다.
- JVM메트릭, 시스템 메트릭, 애플리케이션 시작 메트릭, 스프링MVC, 톰캣 메트릭, 데이터 소스 메트릭, 로그 메트릭, 기타 메트릭
→ 그런데 언제 이걸 하나하나 추가하고 있냐. 그라파나는 이미 만들어둔 대시보드를 가져다가 사용할 수 있는 기능을 제공한다.
!! 저장!!


- 저장을 안해주면 다 날아간다..........................
# 그라파나 - 공유 대시보드 활용 - Spring Boot 2.1 System Monitor
https://grafana.com/grafana/dashboards/
- 다른 사람들이 만들어둔 수 많은 대시보드가 공개되어 있는데, 우리는 스프링부트와 마이크로미터를 사용해서 만든 대시보드를 가져다 사용해보자


- 사용하고자 하는 대시보드에 들어가서, ID를 복사한다. (여기서는 Spring Boot 2.1 System Monitor 사용)
Grafana → New Dashboard → Import dashboard → ID 입력 → Load



- 다음 화면은 바로 위 처럼 일건데, 다른 건 건드릴 필요 없고, data source를 프로메테우스로 선택한다.
- 그리고 Import 버튼을 누르면, 짜잔

# 대쉬보드 톺아보기
# 커넥션

- max가 10개인데, Active가 점점 늘어나서 10개를 넘어가면, 장애가 난다.
# 편집하기




- 이렇게 하면 이제 수정 가능!
# PromQL 수정


- 우측 Edit 눌러서 PromQL 확인 가능
# Jetty 통계 → Tomcat 통계
- 이 대시보드는 톰캣이 아니라 Jetty 라는 웹 서버를 기준으로 통계를 수집한다.


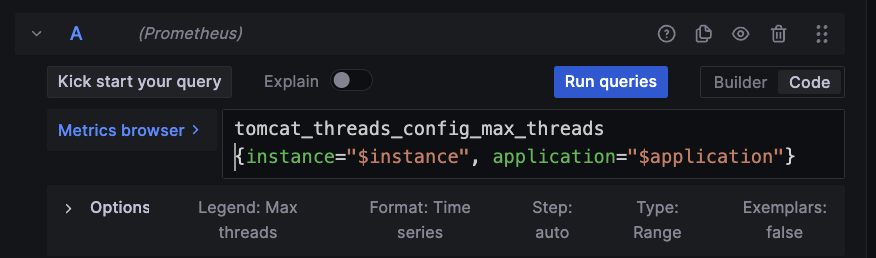
~ 만약 /actuator/prometheus 에 tomcat_threads_config_max_threads 메트릭이 없다면?
- 애플리케이션의 application.yml 에 다음 추가
server:
tomcat:
mbeanregistry:
enabled: true

- 최대가 200개임을 확인했는데, 현재 스레드는 몇개인지 어떻게 확인하지?
→ 바로 아래 보면 Threads 칸이 있다. Edit 클릭

- jetty_threads_current → tomcat_threads_current_threads
- jetty_threads_busy → tomcat_threads_busy_threads
- jetty_threads_idle → 제거
- jetty_threads_jobs → 제거
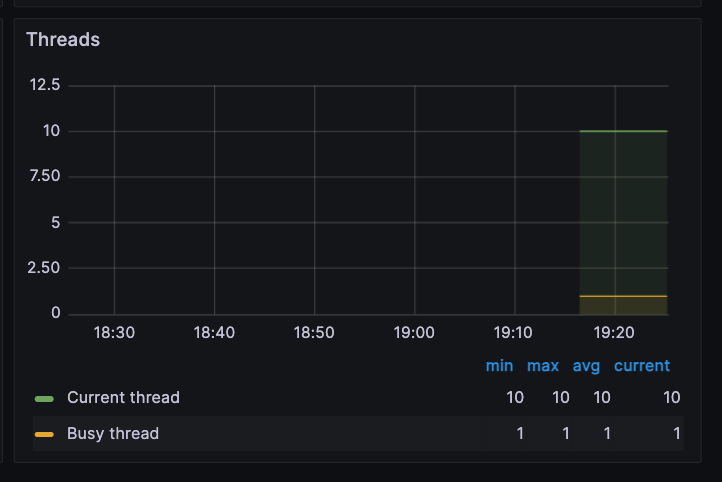
** 이제 저장하고 나가자.

# 그라파나 - 공유 대시보드 활용 - JVM (Micrometer)



'모니터링' 카테고리의 다른 글
| 모니터링 도입기 (2) | 2023.12.21 |
|---|---|
| 모니터링 환경 구성 (1) | 2023.12.21 |
| 모니터링 메트릭 활용 - 스프링부트에서의 예제 (1) | 2023.12.21 |
| 그라파나 - 메트릭을 통한 문제 확인 예제 (1) | 2023.12.18 |
| 모니터링 툴 - 마이크로미터 (0) | 2023.12.18 |


