
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 즉시로딩
- 낙관적락
- 데코레이터
- 비관적락
- 연결리스트
- eager
- 동적sql
- 일대다
- 백트래킹
- SQL프로그래밍
- 스토어드 프로시저
- PS
- querydsl
- BOJ
- exclusive lock
- 연관관계
- FetchType
- dfs
- fetch
- CHECK OPTION
- 유니크제약조건
- JPQL
- execute
- shared lock
- 다대일
- 힙
- 다대다
- 이진탐색
- 스프링 폼
- 지연로딩
- Today
- Total
흰 스타렉스에서 내가 내리지
[JPA] 상속 관계 매핑 본문

슈퍼타입 서브타입 논리 모델을 실제 물리 모델인 테이블로 구현할 때는 3가지 방법이 있다.
1. 조인 전략
- 위의 사진처럼 각각을 모두 테이블로 만들고 조회할 때 조인 사용
2. 단일 테이블 전략
- 테이블을 하나만 사용해서 통합
3. 구현 클래스마다 테이블 전략
- 서브타입마다 하나의 테이블을 만듦. 비추천
1. 조인 전략
맨 위 사진처럼 엔티티 각각을 모두 테이블로 만들고, 자식 테이블이 부모 테이블의 기본 키를 받아서 기본 키 + 외래 키로 사용하는 전략이다.
따라서 조회할 때 조인을 자주 사용한다.
객체는 타입으로 구분할 수 있지만 테이블은 타입의 개념이 없다. 따라서 타입을 구분하는 DTYPE 컬럼을 구분 컬럼으로 사용한다.
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn(name = "DTYPE")
public abstract class Item {
@Id @GeneratedValue
@Column(name = "ITEM_ID")
private Long id;
private String name;
private Integer price;
}
@Entity
@DiscriminatorValue("A")
public class Album extends Item{
private String artist;
}
@Entity
@DiscriminatorValue("M")
public class Movie extends Item{
private String director;
private String actor;
}
@Entity
@DiscriminatorValue("B")
public class Book extends Item{
private String author;
private String isbn;
}@Inheritance(strategy = InheritanceType.JOINED) // 1
@DiscriminatorColumn(name = "DTYPE") // 2
@DiscriminatorValue("A") // 31. 상속 매핑은 부모 클래스에 @Inheritance를 사용해야 한다. (여기서는 Item 추상클래스). 매핑전략은 조인 전략이므로 JOINED
2. 부모 클래스에 구분 컬럼을 지정한다. 이 컬럼으로 저장된 자식 테이블을 구분할 수 있다. 기본값이 DTYPE이라 안써줘도 되긴 하다
3. 엔티티를 저장할 떄 구분 컬럼에 입력할 값을 지정한다.
장점
- 테이블이 정규화된다.
- 외래 키 참조 무결성 제약조건을 활용할 수 있다.
- 저장공간을 효율적으로 사용한다.
단점
- 조회할 때 조인이 많이 사용되므로 성능이 저하될 수 있다.
- 조회 쿼리가 복잡하다.
- 데이터를 등록할 INSERT SQL을 두 번 실행한다.
관련 어노테이션
- @PrimaryKeyJoinColumn, @DiscriminatorColumn, @DiscriminatorValue
2. 단일 테이블 전략
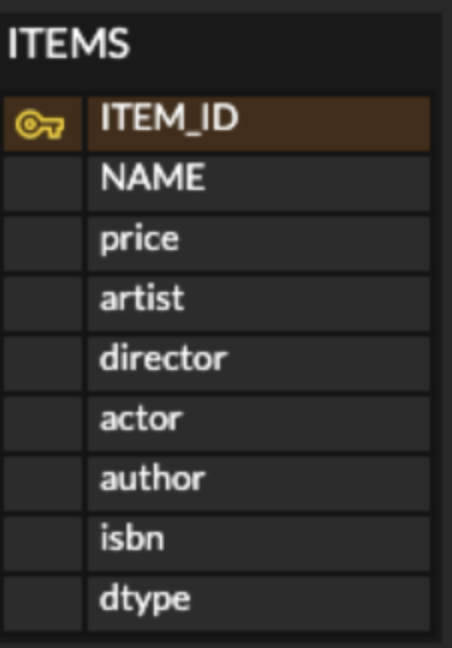
이름 그대로 테이블을 하나만 사용한다.
그리고 구분 컬럼 (DTYPE)으로 어떤 자식 데이터가 저장되었는지 구분한다.
조회할 떄 조인을 사용하지 않으므로 일반적으로 가장 빠르다.
이 전략을 사용할 때 주의점은 자식 엔티티가 매핑한 컬럼은 모두 null을 허용해야 한다.
장점
- 조인이 필요 없으므로 일반적으로 조회 성능이 빠르다.
- 조회 쿼리가 단순하다.
단점
- 자식 엔티티가 매핑한 컬럼은 모두 null을 허용해야 한다.
- 단일 테이블에 모든 것을 저장하므로 테이블이 커질 수 있다. 그러므로 상황에 따라서는 조회 성능이 오히려 느려질 수 있다.
@MappedSuperclass
내가 평소에 자주쓰던 BaseTimeEntitiy

@MappedSuperclass는 테이블과는 관계가 없고 단순히 엔티티가 공통으로 사용하는 매핑 정보를 모아주는 역할을 한다.
부모로부터 물려받은 매핑 정보를 재정의 하려면 @AttributeOverrides나 @AttributeOverride를 사용하고,
연관관계를 재정의 하려면 @AssocationOverrides 나 @AssociationOverride를 사용한다.
@Entity
@AttributeOverride(name = "id", column = @Column(name = "MEMBER_ID"))
public class Member extends BaseEntity{ ... }
@Entity
@AttributeOverrides({
@AttributeOverride(name = "id", column = @Column(name = "MEMBER_ID")),
@AttributeOverride(name = "name", column = @Column(name = "MEMBER_NAME"))
})
public class Member extends BaseEntity{ ... }
다형성 쿼리 - TYPE
JPQL로 부모 엔티티를 조회하면 그 자식 엔티티도 함께 조회한다.
TYPE은 엔티티 상속 구조에서 조회 대상을 특정 자식 타입으로 한정할 때 주로 사용한다.
select i from Item i
where type(i) IN (Book, Movie)
타입 캐스팅 - TREAT
select i from Item i where treat(i as Book).author = 'kim'
'Spring' 카테고리의 다른 글
| [JPA] 복합 키 : 비식별 관계 매핑, @IdClass, @EmbeddedId (0) | 2023.02.11 |
|---|---|
| [JPA] 식별 관계와 비식별 관계 (0) | 2023.02.11 |
| [JPA] 연관관계 - 다대다 @ManyToMany, 복합 키, 식별자 클래스, @IdClass (0) | 2023.02.10 |
| [JPA] 연관관계 - 다대일,일대다,일대일,@ManyToOne,@OneToMany,@OneToOne (0) | 2023.02.10 |
| [JPA] 연관관계의 주인 , mappedBy, 연관관계 (0) | 2023.02.10 |


